
Nell’ambito della gestione dei dati aziendali, una risorsa fondamentale grazie alla quale è possibile acquisire, organizzare e combinare i dati è sicuramente la data preparation. Questa disciplina permette di preparare i dati in base alla loro destinazione, operando su dataset agili e versatili.
Grazie ai moderni dataset è possibile accedere al panorama dei dati aziendali in modo semplice, veloce e intuitivo. Oltre a rendere più semplice il processo di gestione dei dati, grazie alla data preparation è possibile, inoltre, garantire maggiore qualità ai dati stessi.
Scopriamo cos’è la data preparation, in cosa consiste e quali sono le fasi di preparazione dei dati.
Cos’è la data preparation
La data preparation rappresenta un processo fondamentale per assicurare un’ottima data quality aziendale. Questo strumento permette di organizzare ed estrarre i dati di valore, per progettare e implementare strategie data-driven.
La data preparation è uno degli strumenti essenziali in azienda per la realizzazione di una data governance vincente. Vediamo nello specifico cosa si intende per data preparation.
Indispensabile alla preparazione dei dati per un utilizzo di tipo analitico, la data preparation offre un pacchetto di dati già puliti e organizzati, pronti per essere utilizzati. I dati, incanalati all’interno di un dataset, possono essere impiegati in modo semplice e rapido, risparmiando tempo e risorse.
Preparando i dati si raggiunge una buona data quality, in quanto i dati stessi saranno più accessibili e facilmente leggibili. Data governance e data preparation rappresentano due degli strumenti indispensabili per il data management aziendale.
Quando si devono gestire dei dati molto complessi, l’attività preliminare di analisi risulterà più articolata e necessiterà di un’elaborazione più lunga. Le normative legate al trattamento dei dati rendono ancor più complicato il processo di data preparation e gestione dei dati.
Mediante la data preparation, però, è possibile raccogliere, organizzare, combinare, integrare e strutturare i dati. Questi dati, inseriti all’interno di un dataset, vengono utilizzati nell’ambito della business intelligence (analisi descrittiva) o business analytics (analisi predittiva o prescrittiva).
L’analisi dei dati self-service può essere svolta da chiunque, quando viene impiegata la data preparation: uno degli obiettivi di questo strumento è permettere a tutti di utilizzare, modificare e preparare i dati.
L’automazione e l’utilizzo di un parco software evoluto consentono di sfruttare egregiamente le opportunità offerte dal cloud computing. Il futuro della data preparation accoglierà una logica self-service sempre più orientata verso le soluzioni di automazione. L’obiettivo ultimo è quello di realizzare un unico pannello di controllo, che mostri le possibili azioni da compiere in modo ben visibile e di semplice fruizione.
Il ruolo del cloud computing e delle tecniche di machine learning acquisirà sempre maggiore rilevanza, sia durante le operazioni di preparazione che di gestione e ottimizzazione dei dati. Scopriamo ora quali sono gli obiettivi e i vantaggi garantiti dal processo di data preparation.
Gli obiettivi della data preparation
La data preparation genera valore per diverse figure operative interne a un’azienda. Poiché i dati rappresentano un vero e proprio tesoro per quasi tutti i business, la data preparation diventa essenziale per la loro gestione ma anche per la definizione della strategia aziendale.
Generalmente, sono gli specialisti del data management oppure il personale del reparto IT a dover gestire i dataset, implementando i dati e organizzandoli al meglio. Queste figure utilizzano i data warehouse o i data lake, grazie ai quali è possibile organizzare dati strutturati, semi strutturati o non strutturati.
Per la predisposizione dei dataset una figura indispensabile è il data scientist, che si occupa di strutturare i dati e interpretarli. L’obiettivo finale della data preparation è quello di tradurre il singolo dato, estrapolato in modalità grezza da un qualsiasi procedimento digitale, in un dato utilizzabile per l’esecuzione dei processi di analisi. Il dato grezzo presenta piccoli o grandi problemi, non essendo pronto per entrare all’interno di un dataset: occorre prima revisionarlo eliminando ridondanze, errori e lacune.
Tra gli obiettivi del processo di data preparation vi è la scrematura del dato, che viene completato in caso di mancanze e trasformato in un elemento utile ai fini dell’analisi di mercato. In questo modo è possibile creare un dataset ricco di dati coerenti, privi di errori e accurati. I processi di data analytics possono giovare, quindi, di dati corretti piuttosto che di dati parziali o che presentano errori o lacune di vario genere.
Un altro obiettivo della data preparation coinvolge l’attività di ricerca: lo specialista si occuperà di cercare i dati più rilevanti e utili durante il processo di analisi. Gli esperti in business intelligence e nell’analisi dei dati potranno utilizzare dati validi e completi, integrando i vari set in modo da applicarne i risultati anche autonomamente (in caso si disponga di applicazioni di business intelligence self-service).
I vantaggi della data preparation
Il processo di data preparation ha un enorme e positivo impatto sulla data governance dell’azienda. Preparare e organizzare i dati permette, infatti, di ottenere diversi benefici. Di seguito i principali vantaggi raggiungibili mediante le data preparation:
- garantire una buona qualità ai dati che verranno utilizzati nei processi di data analytics e machine learning. Si potranno quindi ottenere risultati validi e attendibili, che permetteranno a loro volta di ottimizzare le performance dei processi aziendali;
- organizzare e preparare i dati sulla base dell’utilizzo e delle occorrenze nell’ambito del processo di analisi;
- predisporre adeguatamente i dati durante il processo di data analytics e machine learning. Ciò si traduce in un’ottimizzazione di tempi e costi legata all’attività di preparazione dei dati;
- supportare adeguatamente le decisioni legate alla strategia business, mediante dataset ricchi di dati di qualità. Un’analisi efficiente consente di raggiungere più facilmente e meglio gli obiettivi aziendali. Un dato approssimativo può rispondere parzialmente, se non in modo errato, alle esigenze legate al processo di data analytics. L’analisi di dati di qualità permette, in ultimo, di raggiungere un elevato ritorno di investimento in tempi anche molto ristretti;
- preparare i dati identificando gli eventuali errori, le lacune o le parzialità, così da offrire dataset il più possibile completi e validi. Per far ciò è possibile utilizzare strumenti e software avanzati che consentono di abbattere il rischio di errore legato all’attività dell’uomo;
- ridurre il carico di lavoro gestito dall’uomo. Gli specialisti, utilizzando software di automazione per la data preparation, piuttosto di occuparsi dell’elaborazione dei dati possono concentrarsi sulle attività strategiche.
Tutti i vantaggi sin ora descritti devono, però, trovare il giusto contesto. Ogni azienda e ogni modello di business necessita di dati validi e completi, ma non tutte le aziende hanno bisogno degli stessi dati. Pertanto, la standardizzazione del processo di data preparation deve essere necessariamente combinata a un approccio “su misura”. Solo in questo modo è possibile ottenere dataset utili e di valore, personalizzando i dati più adeguati al modello di business e alle fasi di elaborazione, gestione e utilizzo dei contenuti.
Il software è indispensabile durante la data preparation, ma ciò che permette di distinguere i dataset e di renderli efficaci è anche l’intervento umano, forte della sua capacità unica nell’analizzare i dati e nella gestione dei processi aziendali. La fase di assessment è fondamentale per determinare la qualità e l’attendibilità dei risultati ottenuti mediante il processo di data analytics. L’interpretazione umana è la leva che consente di trasformare qualsiasi risultato in valore e profitto per il business.
Le fasi della data preparation
La data preparation è un procedimento complesso e piuttosto articolato, soprattutto a seguito dell’introduzione dell’ultimo GDPR. Il recente Regolamento Europeo sulla Protezione dei Dati Personali impone maggiore attenzione durante il processo di trattamento dei dati.
La novità rappresentata dai big data e dalla regola delle 5 V (volume, varietà, velocità, variabilità e veridicità) ha sconvolto notevolmente le attività di gestione dei dati e di data analytics.
Utilizzare dati di valore e dalla qualità superiore permette ai decision maker di scegliere soluzioni data-driven in grado di generare costantemente valore per l’azienda. Ecco perché è fondamentale effettuare il processo di data preparation con la massima attenzione, curando ogni dettaglio.
Le fasi di data preparation vengono svolte mediante specifici software di automazione, grazie ai quali le tempistiche di attività e la complessità relativa a grandi quantitativi di dati si riducono sensibilmente.
Molto spesso tali software di automazione vengono integrati direttamente all’interno di piattaforme di business intelligence o business analytics. Queste applicazioni presentano un’interfaccia grafica intuitiva, che propone una visione unica delle attività mediante dashboard riassuntive. L’impiego del machine learning, inoltre, contribuisce a rendere maggiormente strutturato il dataset e a ottimizzare tutte le fasi di data preparation.
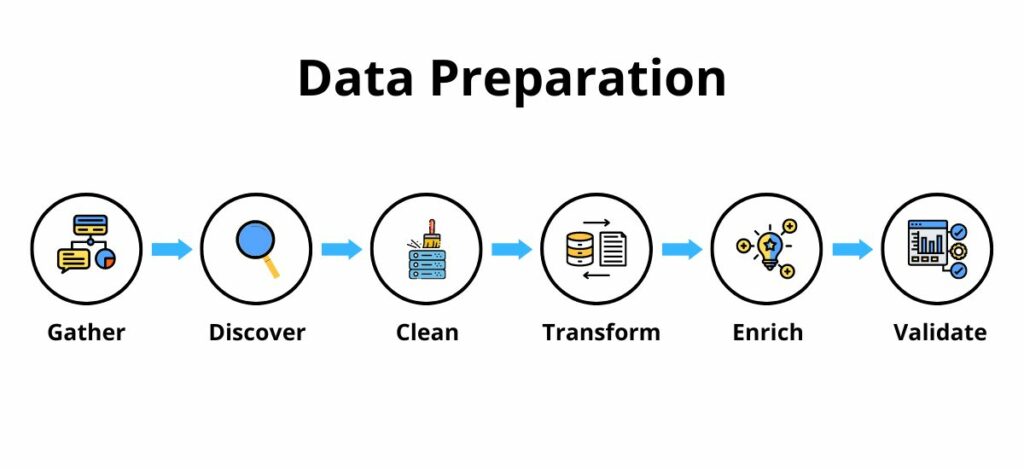
Non esiste un processo unico, in quanto ogni framework e ogni software può essere personalizzato affinché sviluppi soluzioni su misura in base alla tipologia di dati da organizzare. Nonostante ogni azienda predisponga il suo personale piano di preparazione dei dati, gli step principali di questo processo sono raggruppabili in sei attività. Sei, quindi, gli step che definiscono il processo di data preparation, attraverso i quali è possibile realizzare dataset ben organizzati ed efficienti.
Data gathering: la raccolta dei dati
Il primo dei sei step del processo di data preparation consiste nella raccolta dei dati, che possono provenire da fonti come:
- cataloghi dati già esistenti;
- sistemi operativi;
- data warehouse;
- feed di website;
- ERP;
- sistemi IoT;
- dataset esterni.
Durante questa fase occorre eseguire le dovute verifiche, al fine di valutare se e quanto i dati risultano funzionali e coerenti rispetto all’utilizzo che ne verrà fatto.
Data discovery: la scoperta dei dati
Il secondo step del processo di data preparation prevede un’attività esplorativa profonda, finalizzata a comprendere quali possano essere le azioni utili all’ottimizzazione dei dati. In base alla funzione che il dato deve assumere, durante la fase di scoperta dei dati viene analizzata la capacità del dato stesso di rispondere alle esigenze del singolo caso.
La scoperta e la profilazione dei dati permettono di individuare eventuali anomalie o incongruenze, oppure gli attributi e i metadati mancanti, oppure altre problematiche legate al dataset. Di conseguenza, ogni criticità può essere risolta prima di passare alle fasi successive della data preparation. Durante la data discovery il professionista può conoscere meglio i dati e tutti i contenuti dei dataset di cui dispone.
Data cleaning: la fase di pulizia
Con il data cleaning il processo di data preparation raggiunge il suo terzo step. Durante questo frangente, successivo all’esplorazione e profilazione dei dati, si procede con la correzione degli errori, con l’eliminazione delle ridondanze e con l’integrazione di tutte le lacune. Durante la fase di pulizia, il dataset viene completato e reso utilizzabile per le fasi di elaborazione successive. I dati vengono ripuliti e resi qualitativamente impeccabili.
Data transformation e data structuring: trasformazione e strutturazione
In questa quarta fase, il dataset viene reso maggiormente fruibile e operabile. In questo modo, assumerà una funzione perfettamente compatibile con gli altri strumenti a cui serviranno i dati. Gli strumenti che utilizzeranno i dati e che richiederanno l’accesso ad essi per la conseguente elaborazione potranno fruire di dataset completi e modellati in base alle esigenze.
Durante questo quarto passaggio della data preparation, il dataset viene modellato, organizzato e strutturato. Il dataset verrà quindi organizzato e i dati incanalati all’interno di sistemi strutturati sulla base delle esigenze degli strumenti di analisi scelti per le operazioni di data analytics.
La trasformazione e strutturazione dei dati consente di restituire maggiore coerenza al singolo dato, dandogli una struttura e un formato utili alle successive operazioni di analisi. In base alle applicazioni che verranno utilizzate per l’elaborazione, verrà scelto il formato più adatto e questo modello verrà applicato a tutti i dati che compongono il dataset.
Ad esempio, durante questo passaggio occorre uniformare la struttura delle date. Nei sistemi americani si utilizza il formato MM/DD/YY, mentre in altri scenari lo standard è YY/MM/DD. La differenza di formato nella data potrebbe generare errori o confusione nei report, soprattutto qualora non vengano utilizzati tool in grado di rilevare in autonomia le differenze di formato. Ciò restituirebbe un report confuso o poco utilizzabile: anche per questo, ogni dato deve essere uniformato a un modello standard che deve essere rispettato lungo tutto il dataset.
Data enrichment: l’arricchimento dei dati
Il quinto step della data preparation consiste nell’arricchire i dati di nuove informazioni, definendone la struttura e migliorandone la qualità. Il dato viene ottimizzato aggiungendo nuovi dati e informazioni, oppure collegando lo stesso a nuove fonti utili per l’approfondimento delle informazioni stesse. Questo lavoro di ottimizzazione mira ad apportare valore al dato, rendendolo più proficuo e valido per le successive elaborazioni.
La fase di data enrichment viene svolta e modellata sulla base delle utilità determinate dal singolo modello di business.
Data validation e publication: la validazione e pubblicazione
L’ultimo step del processo di data preparation viene svolto con l’obiettivo di validare e pubblicare i dati. Occorre verificare la coerenza, la qualità e l’accuratezza di ogni dato. Per svolgere queste attività, viene messo in atto un processo automatizzato seguendo una specifica routine (definita in base agli obiettivi aziendali).
I dati, dopo queste sei diverse fasi, possono essere caricati nel sistema (data warehouse, data lake o altri repository). Solo allora possono essere utilizzati dagli strumenti di elaborazione che avranno il compito di valorizzarne la funzione informativa ai fini di una corretta analisi.